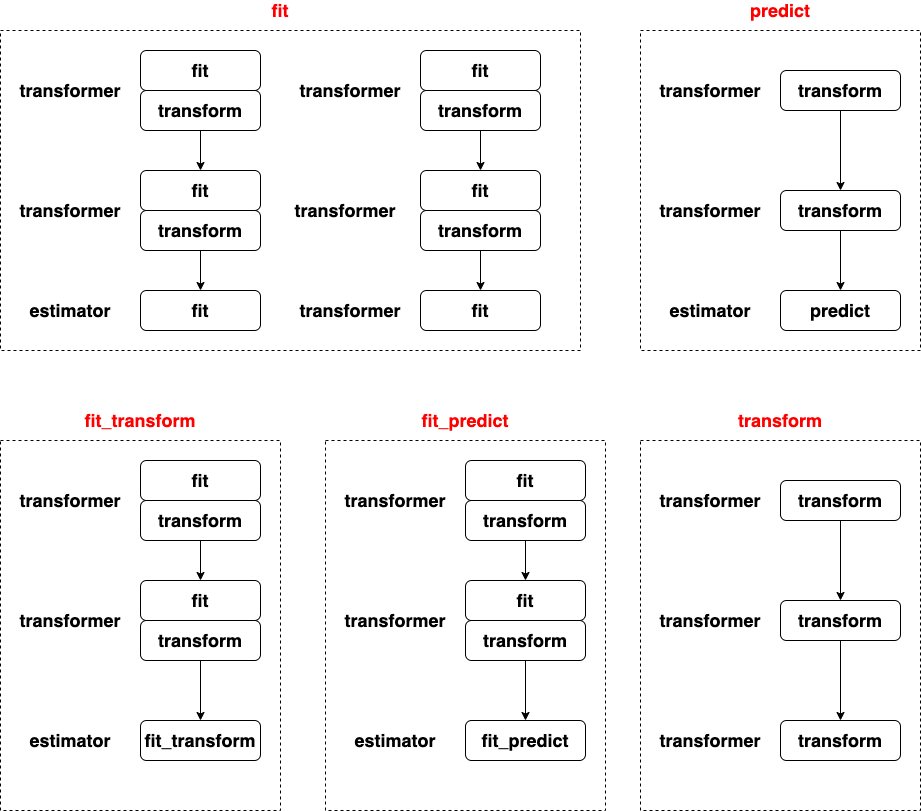
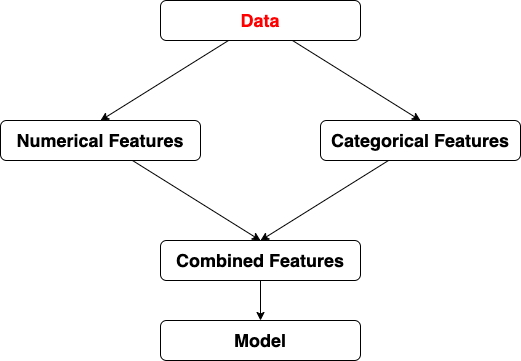
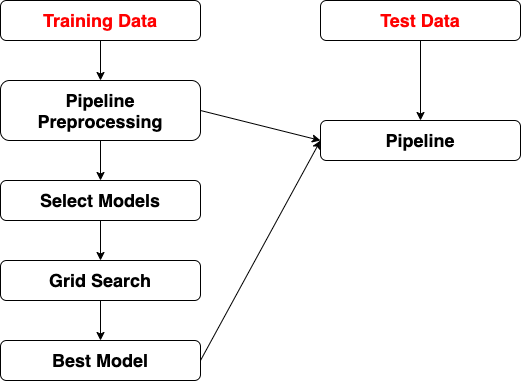
import pandas as pd
data = pd.read_csv('housing.csv')
data.head()
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | median_house_value | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -122.23 | 37.88 | 41.0 | 880.0 | 129.0 | 322.0 | 126.0 | 8.3252 | 452600.0 | NEAR BAY |
| 1 | -122.22 | 37.86 | 21.0 | 7099.0 | 1106.0 | 2401.0 | 1138.0 | 8.3014 | 358500.0 | NEAR BAY |
| 2 | -122.24 | 37.85 | 52.0 | 1467.0 | 190.0 | 496.0 | 177.0 | 7.2574 | 352100.0 | NEAR BAY |
| 3 | -122.25 | 37.85 | 52.0 | 1274.0 | 235.0 | 558.0 | 219.0 | 5.6431 | 341300.0 | NEAR BAY |
| 4 | -122.25 | 37.85 | 52.0 | 1627.0 | 280.0 | 565.0 | 259.0 | 3.8462 | 342200.0 | NEAR BAY |
from sklearn.model_selection import train_test_split
import numpy as np
data_X = data.drop(['median_house_value'], axis = 1) # DataFrame
data_Y = data['median_house_value'] # Series
# split the dataset by categories of median income for stratify split
data['income_cat'] = np.ceil(data['median_income']/1.5)
data['income_cat'].where(data['income_cat'] < 5, 5, inplace=True)
train_X, test_X, train_Y, test_Y = train_test_split(data_X, data_Y, test_size=0.2, random_state=42, stratify = data['income_cat'])
train_X.head()
| longitude | latitude | housing_median_age | total_rooms | total_bedrooms | population | households | median_income | ocean_proximity | |
|---|---|---|---|---|---|---|---|---|---|
| 17606 | -121.89 | 37.29 | 38.0 | 1568.0 | 351.0 | 710.0 | 339.0 | 2.7042 | <1H OCEAN |
| 18632 | -121.93 | 37.05 | 14.0 | 679.0 | 108.0 | 306.0 | 113.0 | 6.4214 | <1H OCEAN |
| 14650 | -117.20 | 32.77 | 31.0 | 1952.0 | 471.0 | 936.0 | 462.0 | 2.8621 | NEAR OCEAN |
| 3230 | -119.61 | 36.31 | 25.0 | 1847.0 | 371.0 | 1460.0 | 353.0 | 1.8839 | INLAND |
| 3555 | -118.59 | 34.23 | 17.0 | 6592.0 | 1525.0 | 4459.0 | 1463.0 | 3.0347 | <1H OCEAN |
from sklearn.base import BaseEstimator, TransformerMixin
class AddAttributes(BaseEstimator, TransformerMixin):
def __init__(self): # no *args or **kargs
pass
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X):
temp = X.copy()
temp["rooms_per_household"] = temp["total_rooms"]/temp["households"]
temp["bedrooms_per_room"] = temp["total_bedrooms"]/temp["total_rooms"]
temp["population_per_household"]=temp["population"]/temp["households"]
return temp
# numerical features
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
('attribs_adder', AddAttributes()),
('imputer', SimpleImputer(strategy="median")),
('std_scaler', StandardScaler()),
])
# categorical features
from sklearn.preprocessing import OneHotEncoder
cat_pipeline = Pipeline([
('cat', OneHotEncoder()),
])
from sklearn.compose import ColumnTransformer
preprocess_pipeline = ColumnTransformer([
("num_pipeline", num_pipeline, ['longitude','latitude','housing_median_age','total_rooms','total_bedrooms','population','households','median_income']),
("cat_pipeline", cat_pipeline, ['ocean_proximity']),
])
# preprocess training data
train_X = preprocess_pipeline.fit_transform(train_X)
# select models
models = [] # save models
from sklearn.linear_model import LinearRegression
models.append(LinearRegression()) # linear regression model
from sklearn.tree import DecisionTreeRegressor
models.append(DecisionTreeRegressor(random_state=42)) # decision tree model
from sklearn.ensemble import RandomForestRegressor # random forest model
models.append(RandomForestRegressor())
from sklearn.svm import SVR
models.append(SVR(kernel="linear")) # Support Vector Regression model
from sklearn.model_selection import cross_val_score
def cross_validation(model, X, Y, k = 10):
scores = cross_val_score(model, X, Y, scoring='neg_mean_squared_error', cv = k);
return np.sqrt(-scores).mean(), np.sqrt(-scores).std() # represent perforance and precision respectively
for model in models:
mean, std = cross_validation(model, train_X, train_Y, 10)
print(mean, std)
68480.58471553595 2845.5843092650834 71035.2888883461 2456.17961798448
/Users/lchen/anaconda3/lib/python3.7/site-packages/sklearn/ensemble/forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22. "10 in version 0.20 to 100 in 0.22.", FutureWarning) /Users/lchen/anaconda3/lib/python3.7/site-packages/sklearn/ensemble/forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22. "10 in version 0.20 to 100 in 0.22.", FutureWarning) /Users/lchen/anaconda3/lib/python3.7/site-packages/sklearn/ensemble/forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22. "10 in version 0.20 to 100 in 0.22.", FutureWarning) /Users/lchen/anaconda3/lib/python3.7/site-packages/sklearn/ensemble/forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22. "10 in version 0.20 to 100 in 0.22.", FutureWarning) /Users/lchen/anaconda3/lib/python3.7/site-packages/sklearn/ensemble/forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22. "10 in version 0.20 to 100 in 0.22.", FutureWarning) /Users/lchen/anaconda3/lib/python3.7/site-packages/sklearn/ensemble/forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22. "10 in version 0.20 to 100 in 0.22.", FutureWarning) /Users/lchen/anaconda3/lib/python3.7/site-packages/sklearn/ensemble/forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22. "10 in version 0.20 to 100 in 0.22.", FutureWarning) /Users/lchen/anaconda3/lib/python3.7/site-packages/sklearn/ensemble/forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22. "10 in version 0.20 to 100 in 0.22.", FutureWarning) /Users/lchen/anaconda3/lib/python3.7/site-packages/sklearn/ensemble/forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22. "10 in version 0.20 to 100 in 0.22.", FutureWarning) /Users/lchen/anaconda3/lib/python3.7/site-packages/sklearn/ensemble/forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22. "10 in version 0.20 to 100 in 0.22.", FutureWarning)
52823.50749113824 2080.6741211545327 111711.14888265522 2754.3053045240267
# grid search
from sklearn.model_selection import GridSearchCV
param_grid = [{'n_estimators': [40, 50, 100], 'max_features': [2, 4, 6, 8, 10, 12]}]
grid_search = GridSearchCV(RandomForestRegressor(), param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(train_X, train_Y)
GridSearchCV(cv=5, error_score='raise-deprecating',
estimator=RandomForestRegressor(bootstrap=True, criterion='mse',
max_depth=None,
max_features='auto',
max_leaf_nodes=None,
min_impurity_decrease=0.0,
min_impurity_split=None,
min_samples_leaf=1,
min_samples_split=2,
min_weight_fraction_leaf=0.0,
n_estimators='warn', n_jobs=None,
oob_score=False, random_state=None,
verbose=0, warm_start=False),
iid='warn', n_jobs=None,
param_grid=[{'max_features': [2, 4, 6, 8, 10, 12],
'n_estimators': [40, 50, 100]}],
pre_dispatch='2*n_jobs', refit=True, return_train_score=False,
scoring='neg_mean_squared_error', verbose=0)
# evaluation scores
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)
52465.8273249397 {'max_features': 2, 'n_estimators': 40}
52216.29134158514 {'max_features': 2, 'n_estimators': 50}
51831.84701400697 {'max_features': 2, 'n_estimators': 100}
50443.16825671332 {'max_features': 4, 'n_estimators': 40}
49917.363055840666 {'max_features': 4, 'n_estimators': 50}
49746.34934276944 {'max_features': 4, 'n_estimators': 100}
49912.60838343643 {'max_features': 6, 'n_estimators': 40}
49579.21983578378 {'max_features': 6, 'n_estimators': 50}
49318.48771177677 {'max_features': 6, 'n_estimators': 100}
50038.81305552377 {'max_features': 8, 'n_estimators': 40}
49549.559912578676 {'max_features': 8, 'n_estimators': 50}
49219.27344720357 {'max_features': 8, 'n_estimators': 100}
49935.18588238241 {'max_features': 10, 'n_estimators': 40}
49672.03488568563 {'max_features': 10, 'n_estimators': 50}
49646.272707301934 {'max_features': 10, 'n_estimators': 100}
50137.96657676582 {'max_features': 12, 'n_estimators': 40}
50158.23620827182 {'max_features': 12, 'n_estimators': 50}
49726.891080028974 {'max_features': 12, 'n_estimators': 100}
test_X_temp = preprocess_pipeline.transform(test_X)
final_model = grid_search.best_estimator_
final_model.predict(test_X_temp)
array([486372.79, 269942.02, 229686.01, ..., 318544.07, 163240. ,
123711. ])
from sklearn.pipeline import make_pipeline
house_price_model = make_pipeline(preprocess_pipeline, final_model)
house_price_model.predict(test_X)
array([486372.79, 269942.02, 229686.01, ..., 318544.07, 163240. ,
123711. ])
import joblib
joblib.dump(house_price_model, 'model.pkl')
['model.pkl']