End-to-End Regression ¶
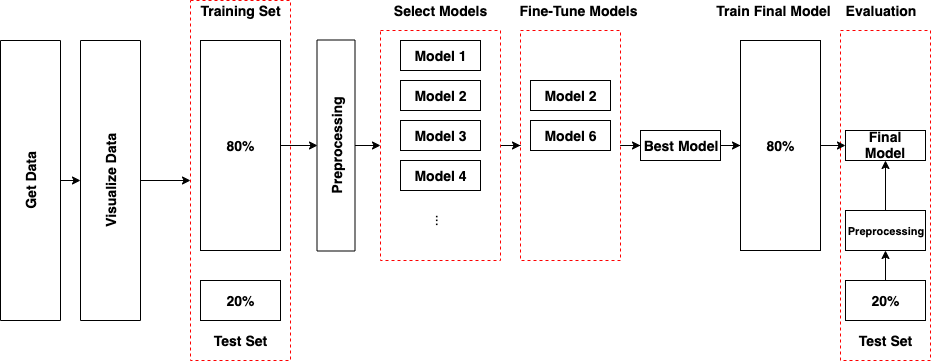
1. Get the Data¶
In [145]:
import pandas as pd
data = pd.read_csv('housing.csv') # California Housing Prices
data.head()
Out[145]:
In [19]:
data.info()
# total_bedrooms has only 20,433 non-null values meaning that 207 districts, need to take care of this
# ocean_proximity is a categorical attribute
In [20]:
# check categorical attribute
data["ocean_proximity"].value_counts()
Out[20]:
In [21]:
# show a summary of the numerical attributes
data.describe()
Out[21]:
In [22]:
plots = data.hist(bins = 50, figsize = (20, 15))

2. Discover and visualize the data to gain insights¶
In [23]:
import matplotlib.pyplot as plt
x = data['longitude']
y = data['latitude']
data.plot(kind='scatter', x='longitude', y='latitude', alpha=0.4, label='population', figsize=(10, 7), c='median_house_value', cmap=plt.get_cmap('jet'), colorbar=True)
Out[23]:

In [24]:
# Add more Attributie Combinations which have higher Correlation with median_house_value
data_copy = data.copy()
data_copy["rooms_per_household"] = data_copy["total_rooms"]/data_copy["households"]
data_copy["bedrooms_per_room"] = data_copy["total_bedrooms"]/data_copy["total_rooms"]
data_copy["population_per_household"]=data_copy["population"]/data_copy["households"]
In [25]:
# Looking for Correlations or Use scatter_matrix
corr_matrix = data_copy.corr()
corr_matrix['median_house_value']
Out[25]:
In [35]:
# Looking for Correlations or Use scatter_matrix
corr_matrix = data_copy.corr()
import seaborn as sns
fig, ax = plt.subplots(figsize=(10,10))
sns.heatmap(corr_matrix, vmax=0.1, center=0, fmt='.2f',
square=False, linewidths=.5, annot=True, cbar_kws={"shrink": 0.7}, ax = ax)
Out[35]:

Feature Selection¶
- the process of selecting the attributes that can make the predicted variable more accurate or eliminating those attributes that are irrelevant and can decrease the model accuracy and quality
Data Correlation¶
- Correlation can help in predicting one attribute from another
- Correlation can (sometimes) indicate the presence of a causal relationship
- Correlation is used as a basic quantity for many modelling techniques
- If your dataset has perfectly positive or negative attributes, the performance of the model will be impacted by multicollinearity. Luckily, decision trees and boosted trees algorithms are immune to multicollinearity by nature.
- The easiest way is to delete or eliminate one of the perfectly correlated features
- use a dimension reduction algorithm such as Principle Component Analysis (PCA)
Correlation¶
- Pearson Correlation Coefficient, used with continuous variables that have a linear relationship
- Spearman Correlation Coefficient, used with variable that have a non-linear relationship
3. Prepare Training Set and Test Set¶
In [280]:
# Read Data
data = pd.read_csv('housing.csv')
# Create Training Set and Test Set
from sklearn.model_selection import train_test_split
# train_test_split
# test_size, ratio of test set
# train_size, ratio of trainning set
# random_state, random seed
# shuffle, whether or not to shuffle the data before splitting
# stratify, data is split in a stratified fashion
import numpy as np
data_X = data.drop(['median_house_value'], axis = 1) # DataFrame
data_Y = data['median_house_value'] # Series
# split the dataset by categories of median income
data['income_cat'] = np.ceil(data['median_income']/1.5)
data['income_cat'].where(data['income_cat'] < 5, 5, inplace=True)
train_X, test_X, train_Y, test_Y = train_test_split(data_X, data_Y, test_size=0.2, random_state=42, stratify = data['income_cat'])
4. Prepare the Data for Machine Learning Algorithms¶
In [281]:
#Custom Transformer, add three features
from sklearn.base import BaseEstimator, TransformerMixin
class AddAttributes(BaseEstimator, TransformerMixin):
def __init__(self): # no *args or **kargs
pass
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X):
X["rooms_per_household"] = X["total_rooms"]/X["households"]
X["bedrooms_per_room"] = X["total_bedrooms"]/X["total_rooms"]
X["population_per_household"]=X["population"]/X["households"]
return X
In [140]:
train_X_num = train_X.drop("ocean_proximity", axis=1)
attr_adder = AddAttributes()
temp = attr_adder.transform(data_num)
In [141]:
# Data Cleaning
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(strategy="median")
temp_2 = imputer.fit_transform(train_X_num)
In [142]:
# Convert Text and Categorical Attributes to Dummy Attributes
from sklearn.preprocessing import LabelBinarizer
encoder = LabelBinarizer()
temp_3 = encoder.fit_transform(train_X['ocean_proximity'])
Scaling variables¶
- zero-mean normalization: $x_{i}=(x_{i}−mean(x_{i}))/std(x_{i})$, standardization
- Min-max normalization: $x_{i}=(x_{i}−min(x_{i})/(max(x_{i})−min(x_{i}))$ normalizaiton, recommendation
In [143]:
# feature scaling
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
temp_4 = scaler.fit_transform(train_X_num)
Transformation Pipelines¶
In [282]:
class DataFrameSelector(BaseEstimator, TransformerMixin):
def __init__(self, attribute_names):
self.attribute_names = attribute_names
def fit(self, X, y=None):
return self
def transform(self, X):
return X[self.attribute_names]
In [283]:
# Create Pipeline for Numeric Columns
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
num_pipeline = Pipeline([
("select_numeric", DataFrameSelector(['longitude','latitude','housing_median_age','total_rooms','total_bedrooms','population','households','median_income',])),
('attribs_adder', AddAttributes()),
('imputer', SimpleImputer(strategy="median")),
('std_scaler', StandardScaler()),
])
#train_X_tr = num_pipeline.fit_transform(train_X)
In [284]:
# Create Pipeline for Categorical Columns
from sklearn.preprocessing import OneHotEncoder
cat_pipeline = Pipeline([
("select_numeric", DataFrameSelector(['ocean_proximity'])),
('cat', OneHotEncoder()),
])
#data_cat_tr = cat_pipeline.fit_transform(train_X)
In [285]:
# Merge Numeric Columns and Categorical Columns
from sklearn.pipeline import FeatureUnion
preprocess_pipeline = FeatureUnion(transformer_list=[
("num_pipeline", num_pipeline),
("cat_pipeline", cat_pipeline),
])
In [286]:
train_X = preprocess_pipeline.fit_transform(train_X).toarray()
5. Select and Train a Model¶
- Do not spending too much time tweaking the hyperparameters, the goal is to shortlist a few promissing models
In [287]:
models = [] # save models
from sklearn.linear_model import LinearRegression
models.append(LinearRegression()) # linear regression model
from sklearn.tree import DecisionTreeRegressor
models.append(DecisionTreeRegressor(random_state=42)) # decision tree model
from sklearn.ensemble import RandomForestRegressor # random forest model
models.append(RandomForestRegressor())
from sklearn.svm import SVR
models.append(SVR(kernel="linear")) # Support Vector Regression model
In [225]:
from sklearn.model_selection import cross_val_score
def cross_validation(model, X, Y, k = 10):
scores = cross_val_score(model, X, Y, scoring='neg_mean_squared_error', cv = k);
return np.sqrt(-scores).mean(), np.sqrt(-scores).std() # represent perforance and precision respectively
In [228]:
for model in models:
mean, std = cross_validation(model, train_X, train_Y, 10)
print(mean, std)
6. Fine-Tune Your Model¶
- Select a couple of models having reasonable performance from above
- Fine-tune these models to generate the best model
Grid Search¶
In [260]:
from sklearn.model_selection import GridSearchCV
param_grid = [{'n_estimators': [40, 50, 100], 'max_features': [2, 4, 6, 8, 10, 12]}]
grid_search = GridSearchCV(RandomForestRegressor(), param_grid, cv=5, scoring='neg_mean_squared_error')
grid_search.fit(train_X, train_Y)
Out[260]:
In [261]:
grid_search.best_params_ # best combination of parameters
Out[261]:
In [262]:
grid_search.best_estimator_ # best model
# If GridSearchCV is initialized with refit=Ture (which is the default),
# then once it finds the best estimator using cross-validation, it retrains it on the whole training set
Out[262]:
In [274]:
# evaluation scores
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)
Randomized Search¶
In [237]:
# Select a random combination of hyperparameter at every iteration
from sklearn.model_selection import RandomizedSearchCV
param_random = {'n_estimators': [50, 100, 150], 'max_features': [2, 4, 6, 8, 10, 12]}
random_search = RandomizedSearchCV(RandomForestRegressor(), param_random, cv=5, scoring='neg_mean_squared_error', n_iter = 10)
random_search.fit(train_X, train_Y)
Out[237]:
In [238]:
random_search.best_params_ # best combination of parameters
Out[238]:
In [239]:
cvres = random_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)
7. Ensemble Methods¶
8. Analyze the Best Models and Their Errors¶
In [74]:
# Look at the specific errors, try to understand why it makes them and what could fix the problem,
# e.g., adding extra features or getting rid of uninformative ones, cleaning up outliers
feature_importance = grid_search.best_estimator_.feature_importances_
l = zip(feature_importance, data_X.columns)
for e in l:
print(e)
9. Train Final Model¶
In [288]:
final_model = grid_search.best_estimator_
#final_model.fit(train_X, train_Y) # Do not have to retain, it has been done by GridSearchCV or RandomizedSearchCV
10. Evaluate System on the Test Set¶
In [289]:
test_X = preprocess_pipeline.transform(test_X).toarray()
In [290]:
# Evaluate test dataset
from sklearn.metrics import mean_squared_error
predictions = final_model.predict(test_X)
MSE = mean_squared_error(test_Y, predictions)
RMSE = np.sqrt(MSE)
RMSE
Out[290]:
In [291]:
# 95% confidence interval for the generalizaiton error
from scipy import stats
confidence = 0.95
squared_errors = (predictions - test_Y) ** 2
np.sqrt(stats.t.interval(confidence, len(squared_errors) - 1,
loc=squared_errors.mean(),
scale=stats.sem(squared_errors)))
Out[291]:
11. Deliver Model¶
In [271]:
import pickle
f = open('model.pkl', 'wb');
pickle.dump(final_model, f, -1);
In [ ]:
import joblib
jolib.dump(final_model, 'model.pkl')
#model_loaded = joblib.load('model.pkl')