Resampling ¶
Validation Set Approach¶

the error rate of validation set is used to estimate the error rate of test set¶
Cons¶
- the validation estimate of the test error rate can be highly variable. This means that when it is repeated, it gives different results, often very different results
- the validation set error rate may tend to overestimate the test error rate
Leave-One-Out Cross Validaiton (LOOCV)¶
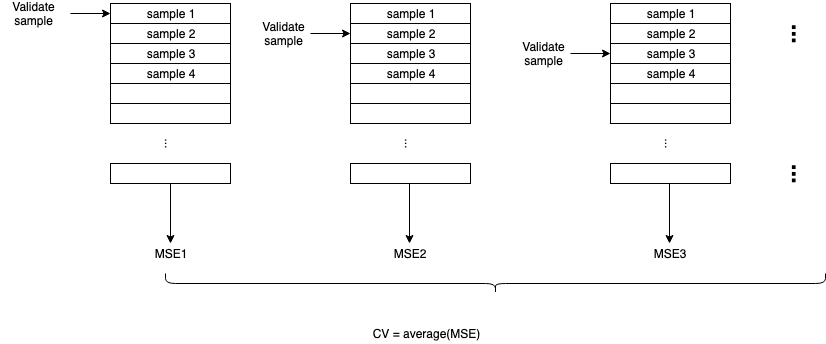
Repeat training and validaiton n times, n is the number of samples. Each time use n-1 samples as training set and 1 sample as validation set.
Pros¶
- Far less bias, not to overestimate the test error rate
- LOOCV yield the same results, no randomness in hte training/validation set splits
Cons¶
- training sets are highly correlated, tends to have higher variance
Application¶
- LOOCV is often better than k-fold CV when the size of the dataset is small
k-fold Cross Validation¶
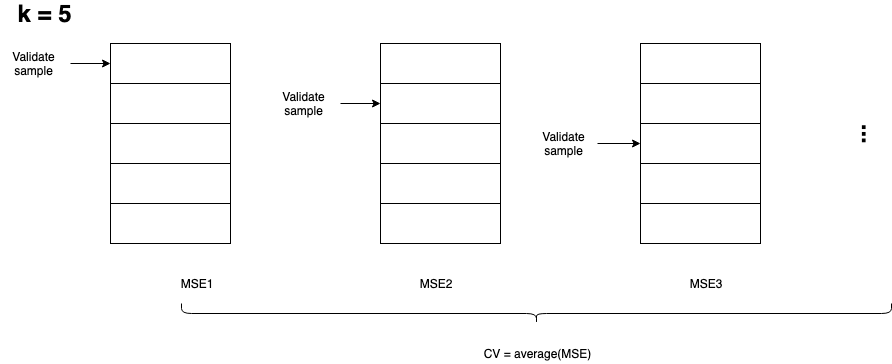
Dataset is randomly divided into k groups, or folds, of approximately equal size. Repeat training and validation k time, each time use k-1 folds as training set and 1 fold as validation set. k = 5 or k = 10.
Pros¶
- More accurate estimates of the test error rate than LOOCV
- Higher bias and lower variance than LOOCV, is a bias-variance trade-off
Application¶
- unless the dataset were very small, use k-fold cross-validation
CV on Regression and Classification¶
- Regression, use MSE
- Classification
Trained using the number of misclassified observations, or log loss Evaluated using precision/recall
Bootstrap¶
- Randomly sampling, with replacement, from an original dataset for use in obtaining statistical estimates. The generated dataset is a bootstrap sample set. Use boostrap sample set as the training set.
- The unselected samples in the original dataset is a out-of-bag (OOB) sample. Use the OOB sample set as the validation set.
Application¶
- Small sample size
- Non-normal distribution of the sample
- A test of means for two samples
- Not as sensitive to N
Configuration¶
- In machine learning, it is common to use a sample size that is the same as the original dataset.
- A minimum number of repetitions might be 20 or 30 repetitions. Ideally, the sample of estimates would be as large as possible given the time resources, with hundreds or thousands of repeats.
Final Machine Learning Model¶
- Use resampling methods to choose a model which has best performance
- Applying the chosen machine learning model on all of your data
- Save the model for later or operational use.
- Make predictions on new data.