Main Challenges of Machine Learning¶
Unreasonable Effectiveness of Data
- Data matters more than algorithms
- Google Paper
Nonrepresentative Training Data
- It is crucial to use a training set that is representative of the new cases you want to generalize to
- If the sample is too small, have sample noise
- If nonrepresentative large samples, have sampling bias
Poor-Quality Data
- Training data is full of errors, outliers, and noise
- If some instances are clearly outliers, it may help to simply discard them or try to fix the errors manually
- If some instances are missing a few features, decide whether you want to ignore this attribute altogether, ignore these instances, fill in the missing values, or train on model with the feature and one model without it
Irrelevant Features
The system will only be capable of learning if the training data contains enough relevant features and too many irrelevant ones
- Feature Engineering
- Feature selection: selecting the most useful features to train on among existing features
- Feature extraction: combining existing features to produce a more useful one, such as, dimensionality reduction
- Creating new features by gathering new data
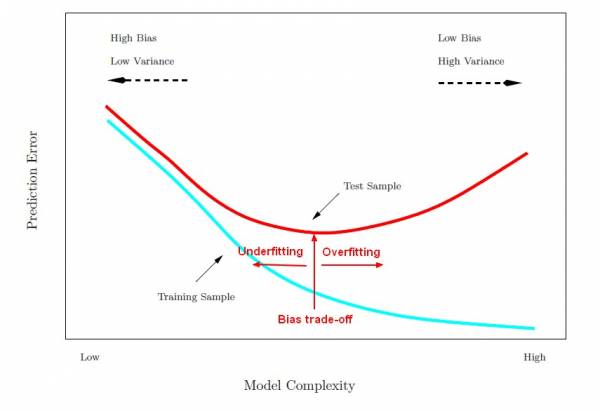
Overfitting
The model performs well on the training data, but does not generalize well Solutions
- To simplify the model
- To gather more training data
- To reduce the noise in the training data
Underfitting
The model is to simple to learn the underlying structure of the data Solutions
- Selecting a more powerful model
- Feeding better features to the learning algorithm
- Reducing the constraints on the model, reducing the regularizaiton hyperparameter
- Bias referes to the error that is introduced by approximating a real-life problem
- Variance is due to the model's excessive sensitivity to small variations in the training data, refers to the amount by which factor would change if we estimated it using a different training data set
- Irreducible error is due to the noisiness of the data itself. The only way to reduce this part of the error is to clean up the data
- Higher the degrees of freedom, may cause overfitting, low bias, high variance
- Lower the degrees of freedom, may cause underfitting, high bias, low variance