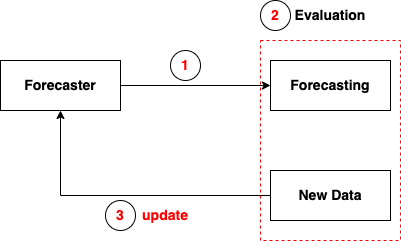
Model Creation¶

import warnings
warnings.filterwarnings('ignore')
from sktime.datasets import load_longley
_, y = load_longley() # 16*5
y.head()
| GNPDEFL | GNP | UNEMP | ARMED | POP | |
|---|---|---|---|---|---|
| Period | |||||
| 1947 | 83.0 | 234289.0 | 2356.0 | 1590.0 | 107608.0 |
| 1948 | 88.5 | 259426.0 | 2325.0 | 1456.0 | 108632.0 |
| 1949 | 88.2 | 258054.0 | 3682.0 | 1616.0 | 109773.0 |
| 1950 | 89.5 | 284599.0 | 3351.0 | 1650.0 | 110929.0 |
| 1951 | 96.2 | 328975.0 | 2099.0 | 3099.0 | 112075.0 |
from sktime.forecasting.model_selection import temporal_train_test_split
y_train, y_test = temporal_train_test_split(y, test_size=4) # hold out last 4 years
from sktime.transformations.series.detrend import Deseasonalizer
from sktime.transformations.series.func_transform import FunctionTransformer
from sktime.forecasting.trend import PolynomialTrendForecaster
from sktime.transformations.series.detrend import Detrender
def forward_transform(y):
return y*10
def backward_transform(y):
return y/10
trend = PolynomialTrendForecaster(degree=1)
# preprocessing pipeline
preprocessing = Detrender(forecaster=trend) \
* FunctionTransformer(func = forward_transform, inverse_func = backward_transform)
# preprocess training data
y_train_preprocessing = preprocessing.fit_transform(y_train)
import pandas as pd
def get_evaluation(df, name = 'test_MeanAbsoluteError'):
"""Extract evaluation information from cross-validation results
"""
evaluation = pd.DataFrame(columns = list(y.columns))
for trial in range(df.shape[0]):
row = {}
for index, feature in enumerate(list(y.columns)):
row[feature] = df[name][trial][index]
evaluation = evaluation.append(row, ignore_index = True)
return evaluation
# select model with a loop
import numpy as np
from sktime.forecasting.ets import AutoETS
from sktime.forecasting.var import VAR
from sktime.forecasting.varmax import VARMAX
from sktime.forecasting.model_evaluation import evaluate
from sktime.forecasting.model_selection import ExpandingWindowSplitter
from sktime.performance_metrics.forecasting import MeanAbsoluteScaledError
models = {'VAR': VAR(),
'AutoETS': AutoETS()}
fh=np.arange(1, 4)
cv = ExpandingWindowSplitter(step_length=4, fh=fh, initial_window=6)
loss = MeanAbsoluteScaledError(multioutput = 'raw_values')
for model in models:
df = evaluate(forecaster=models[model], y=y, cv=cv, strategy="refit", scoring = loss, return_data=True)
evaluation = get_evaluation(df, name = 'test_MeanAbsoluteScaledError')
print(model, ': ', evaluation.mean().mean())
VAR : 1.3518417095558566 AutoETS : 302.51897414372365
# select model with MultiplexForecaster
from sktime.forecasting.compose import MultiplexForecaster
from sktime.forecasting.model_selection import ForecastingGridSearchCV
models = MultiplexForecaster(
forecasters=[
('VAR', VAR()),
('AutoETS', AutoETS(auto=True, sp=12, n_jobs=-1))
])
fh=np.arange(1, 4)
cv = ExpandingWindowSplitter(step_length=4, fh=fh, initial_window=6)
forecaster_param_grid = {"selected_forecaster": ['VAR', 'AutoETS']}
model_selection = ForecastingGridSearchCV(models, cv=cv, param_grid=forecaster_param_grid)
model_selection.fit(y_train_preprocessing)
model_selection.best_forecaster_, model_selection.best_score_
(MultiplexForecaster(forecasters=[('VAR', VAR()),
('AutoETS',
AutoETS(auto=True, n_jobs=-1, sp=12))],
selected_forecaster='VAR'),
12.55874857841008)
# list hyperparameters of the select model
model_selected = VAR()
model_selected.get_params()
{'dates': None,
'freq': None,
'ic': None,
'maxlags': None,
'method': 'ols',
'missing': 'none',
'random_state': None,
'trend': 'c',
'verbose': False}
from sktime.forecasting.model_selection import ForecastingGridSearchCV, SlidingWindowSplitter
# create search list for each needed hyperparameter
param_grid = {'ic':['aic', 'fpe', 'hqic', 'bic', None], 'trend': ['c', 'ct', 'ctt', 'n']}
# create cross-validation approach
cv = SlidingWindowSplitter(window_length=10)
# grid search
gscv = ForecastingGridSearchCV(model_selected, strategy="refit", cv=cv, param_grid=param_grid)
fine_tuning = gscv.fit(y_train)
# get the best model
# the best model has been trained by the whole training data
model_best = fine_tuning.best_forecaster_
fine_tuning.best_params_
{'ic': None, 'trend': 'n'}
import numpy as np
# build pipeline
forecaster = (preprocessing * model_best)
fh = np.arange(1, 5)
forecaster.fit(y_train)
TransformedTargetForecaster(steps=[Detrender(forecaster=PolynomialTrendForecaster()),
FunctionTransformer(func=<function forward_transform at 0x1317374c0>,
inverse_func=<function backward_transform at 0x131737560>),
VAR(trend='n')])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. TransformedTargetForecaster(steps=[Detrender(forecaster=PolynomialTrendForecaster()),
FunctionTransformer(func=<function forward_transform at 0x1317374c0>,
inverse_func=<function backward_transform at 0x131737560>),
VAR(trend='n')])from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
# predict on test period
y_pred = forecaster.predict(fh)
# evaluation with metric
mean_absolute_percentage_error(y_test, y_pred, symmetric=False, multioutput = 'raw_values')
array([0.04696546, 0.0090055 , 0.10562995, 0.08357784, 0.00866678])
y_pred
| GNPDEFL | GNP | UNEMP | ARMED | POP | |
|---|---|---|---|---|---|
| Period | |||||
| 1959 | 109.820356 | 481987.985076 | 3521.913248 | 2708.821245 | 123198.414594 |
| 1960 | 110.185181 | 500509.160600 | 3688.966919 | 2839.922126 | 124772.422035 |
| 1961 | 109.431670 | 521129.199354 | 3701.676250 | 2797.859163 | 126323.296072 |
| 1962 | 108.267828 | 541203.882154 | 3787.301808 | 2670.374107 | 127921.498483 |