Model Creation¶

import warnings
warnings.filterwarnings('ignore')
from sktime.datasets import load_airline
from sktime.forecasting.model_selection import temporal_train_test_split
y = load_airline() # 144 for 12 years
y_train, y_test = temporal_train_test_split(y, test_size=36) # hold out last 3 years
from sktime.utils.plotting import plot_series
plot_series(y_train, y_test, labels=["y_train", "y_test"])
(<Figure size 1600x400 with 1 Axes>, <Axes: ylabel='Number of airline passengers'>)

from sktime.transformations.series.detrend import Deseasonalizer
from sktime.transformations.series.func_transform import FunctionTransformer
from sktime.forecasting.trend import PolynomialTrendForecaster
from sktime.transformations.series.detrend import Detrender
def forward_transform(y):
return y*10
def backward_transform(y):
return y/10
trend = PolynomialTrendForecaster(degree=1)
# preprocessing pipeline
preprocessing = Detrender(forecaster=trend) \
* Deseasonalizer(model="additive", sp=12) \
* FunctionTransformer(func = forward_transform, inverse_func = backward_transform)
# preprocess training data
y_train_preprocessing = preprocessing.fit_transform(y_train)
plot_series(y_train_preprocessing, labels=["y_train_preprocessing"])
(<Figure size 1600x400 with 1 Axes>, <Axes: ylabel='Number of airline passengers'>)

# select model with a loop
from sktime.forecasting.ets import AutoETS
from sktime.forecasting.naive import NaiveForecaster
from sktime.forecasting.arima import AutoARIMA
from sktime.forecasting.model_evaluation import evaluate
from sktime.forecasting.model_selection import ExpandingWindowSplitter
models = {'Naive': NaiveForecaster(strategy="last", sp=12),
'AutoETS': AutoETS(auto=True, sp=12, n_jobs=-1),
'AutoARIMA': AutoARIMA(sp=12, suppress_warnings=True)}
cv = ExpandingWindowSplitter(step_length=12, fh=[1, 2, 3, 4], initial_window=72)
for model in models:
df = evaluate(forecaster=models[model], y=y_train_preprocessing, cv=cv, strategy="refit", return_data=True)
print(model, ':', df['test_MeanAbsolutePercentageError'].mean())
Naive : 11.910423031846037 AutoETS : 4.107304800952965 AutoARIMA : 2.2138522877247544
# select model with MultiplexForecaster
from sktime.forecasting.compose import MultiplexForecaster
from sktime.forecasting.model_selection import ForecastingGridSearchCV
models = MultiplexForecaster(
forecasters=[
('Naive', NaiveForecaster(strategy="last", sp=12)),
('AutoETS', AutoETS(auto=True, sp=12, n_jobs=-1)),
('AutoARIMA', AutoARIMA(sp=12, suppress_warnings=True))
])
cv = ExpandingWindowSplitter(step_length=12, fh=[1, 2, 3, 4], initial_window=72)
forecaster_param_grid = {"selected_forecaster": ['Naive', 'AutoETS', 'AutoARIMA']}
model_selection = ForecastingGridSearchCV(models, cv=cv, param_grid=forecaster_param_grid)
model_selection.fit(y_train_preprocessing)
model_selection.best_forecaster_, model_selection.best_score_
(MultiplexForecaster(forecasters=[('Naive', NaiveForecaster(sp=12)),
('AutoETS',
AutoETS(auto=True, n_jobs=-1, sp=12)),
('AutoARIMA',
AutoARIMA(sp=12, suppress_warnings=True))],
selected_forecaster='AutoARIMA'),
2.2138522877247544)
# list hyperparameters of the select model
model_selected = AutoARIMA(suppress_warnings=True)
model_selected.get_params()
{'D': None,
'alpha': 0.05,
'concentrate_scale': False,
'd': None,
'enforce_invertibility': True,
'enforce_stationarity': True,
'error_action': 'warn',
'hamilton_representation': False,
'information_criterion': 'aic',
'max_D': 1,
'max_P': 2,
'max_Q': 2,
'max_d': 2,
'max_order': 5,
'max_p': 5,
'max_q': 5,
'maxiter': 50,
'measurement_error': False,
'method': 'lbfgs',
'mle_regression': True,
'n_fits': 10,
'n_jobs': 1,
'offset_test_args': None,
'out_of_sample_size': 0,
'random': False,
'random_state': None,
'scoring': 'mse',
'scoring_args': None,
'seasonal': True,
'seasonal_test': 'ocsb',
'seasonal_test_args': None,
'simple_differencing': False,
'sp': 1,
'start_P': 1,
'start_Q': 1,
'start_p': 2,
'start_params': None,
'start_q': 2,
'stationary': False,
'stepwise': True,
'suppress_warnings': True,
'test': 'kpss',
'time_varying_regression': False,
'trace': False,
'trend': None,
'update_pdq': True,
'with_intercept': True}
from sktime.forecasting.model_selection import ForecastingGridSearchCV, SlidingWindowSplitter
# create search list for each needed hyperparameter
param_grid = {"sp": [3, 7, 12, 14], 'alpha': [0.03, 0.05, 0.1]}
# create cross-validation approach
cv = SlidingWindowSplitter(initial_window=int(len(y_train) * 0.8), window_length=72)
# grid search
gscv = ForecastingGridSearchCV(model_selected, strategy="refit", cv=cv, param_grid=param_grid)
fine_tuning = gscv.fit(y_train)
# get the best model
# the best model has been trained by the whole training data
model_best = fine_tuning.best_forecaster_
fine_tuning.best_params_
{'alpha': 0.1, 'sp': 12}
import numpy as np
# build pipeline
forecaster = (preprocessing * model_best)
fh = np.arange(1, 37)
forecaster.fit(y_train)
TransformedTargetForecaster(steps=[Detrender(forecaster=PolynomialTrendForecaster()),
Deseasonalizer(sp=12),
FunctionTransformer(func=<function forward_transform at 0x13c2027a0>,
inverse_func=<function backward_transform at 0x13c201da0>),
AutoARIMA(alpha=0.1, sp=12,
suppress_warnings=True)])In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. TransformedTargetForecaster(steps=[Detrender(forecaster=PolynomialTrendForecaster()),
Deseasonalizer(sp=12),
FunctionTransformer(func=<function forward_transform at 0x13c2027a0>,
inverse_func=<function backward_transform at 0x13c201da0>),
AutoARIMA(alpha=0.1, sp=12,
suppress_warnings=True)])from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
# predict on test period
y_pred = forecaster.predict(fh)
# evaluation with metric
mean_absolute_percentage_error(y_test, y_pred, symmetric=False)
0.054972262355267615
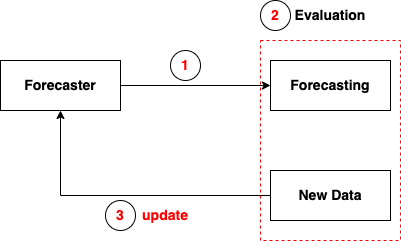
forecaster.update(y[[-36]]) # the first month of the last 3 years
fh = np.arange(1, 36)
y_pred_1958Jan = forecaster.predict(fh)
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
y_test = y_test[1:]
mean_absolute_percentage_error(y_test, y_pred_1958Jan, symmetric=False)
0.055202254223257655
plot_series(y[:-35], y[-35:], y_pred_1958Jan, labels=["y_train_update", "y_test", "y_pred_update"])
(<Figure size 1600x400 with 1 Axes>, <Axes: ylabel='Number of airline passengers'>)
