Introduction
Stack
Elasticsearch
- A distributed search engine
- Implemented RESTful APIs over HTTP using JSON
Logstash
- Collect, transform, and send logs to a range of target systems, such as Elasticsearch
Kibana
- A user interface to search for and visualize data using the REST APIs on Elasticsearch
Beats
- Collect and ship network packet data to Elasticsearch with a collection of lightweight agents
Application Performance Monitoring (APM)
- APM, Logs, Metrics, and Uptime apps forms the Observability solution
Security Information and Event Management (SIEM)
- Security analytics functionality
Endpoint Detection and Response (EDR)
- EDR and SIEM capabilities formed the Security solution
Elasticsearch Architecture
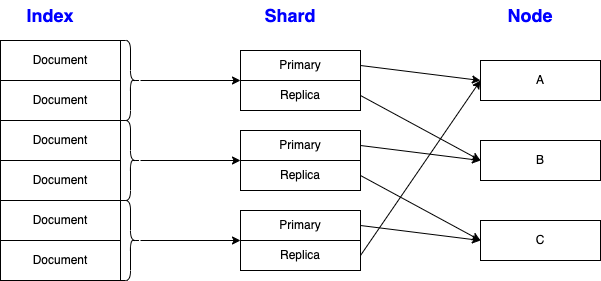
Cluster, Node, and Shard
shard size
- a few GB and a few tens of GB
- the more shards, the more overhead
number of primary shards of an index
- fixed at the time that an index is created
- the larger the shard size, the longer it takes to move shards around when Elasticsearch needs to rebalance a cluster
the number of replica shards of a primary shard
- can be changed at any time
- not placed on the same node as its primary shards
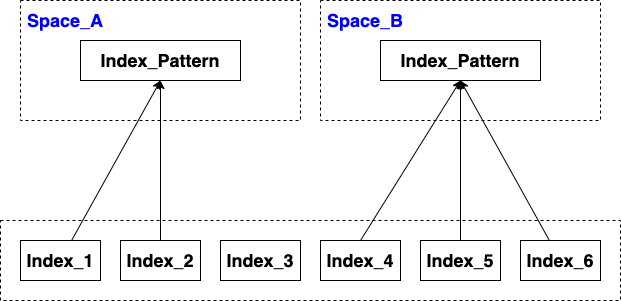
Space, and Index
Score
a value that represents how relevant a document is to a specific query
Term Frequency (TF)
- how many each searched term appear in a document
Inverse Document Frequency (ITF)
Terms
field, column
document, row, base unit of storage
- _index, the index where the document resides
- _type, the type that the document represents
- _id, the unique identifier for the document
- _score, a way of determining how relevant a match is to the query
Mapping, defines how a document, its fields, and its metadata are stored in Elasticsearch
Index, table, the largest unit of data in Elasticsearch, are logical partitions of documents
- documents group into an index in a logic manner
- lowercase names
- no limit to how many documents that can be stored on each index
- not actually store documents, a virtual thing that tracks where the documents are store
Shard
- is where documents are stored
- a single Lucene index
- primary and replica
- adding replica to increase searching speed
Bucket
- A set of documents in Kibana that have certain characteristics in common, such as color, distance, or date range
Bucket aggregation, an aggregation that creates buckets of documents
Metrics aggregations, calculate metrics based on the values of fields in documents. Metrics can be computed for buckets/groups of data
Analyzer
- used to tell elasticsearch how the text should be indexed and searched
- Character filter, used to strip off some unused characters or change some characters
- Tokenizer, breaks a text into individual tokens(or words) and it does that based on certain factors
- Token filter: it receives the tokens and then apply some filters
Space
Namespace
Deployment
Integration
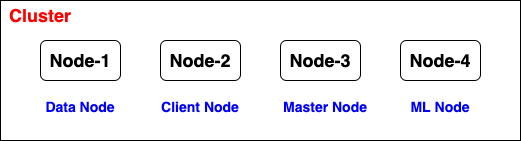
Node, Elasticsearch instance
- Data node, stores data and executes data-related operations, such as search and aggregation
- Master node, in charge of cluster-wide management and configuration actions, such as adding and removing nodes
- Client node, forwards cluster requests to the master node and data-related requests to data nodes
- Ingestion node, pre-process documents before indexing
- Machine Learning node, enable machine learning tasks
Cluster, database, the set of indices available are grouped in a cluster
- A group of one or more connected Elasticsearch nodes
- Each cluster has a unique identifier. By default, its name is “elasticsearch”
- cluster APIs, such as /_cluster/health
Reference