String
String
Strings of characters, immutable
#!/usr/bin/python
s = 'Hello World!';
#access element
print s[0]; #H
#slicing
print s[:2]; #He
#slice
sl = slice(0, 10, 2);
print s[sl]; #HloWr
#concatenation
print s+' ...';
#repeat
print s*2;
#in
if 'H' in s:
print 'Contain H';
#raw string, suppresses actual meaning of escape characters
print r'raw string\n';
#!/usr/bin/python
s = 'Hello World!';
#capitalize, capitalizes first letter of string
print s.capitalize();
#center
print s.center(20, '*');
#count
print s.count('l');
#endswith
if s.endswith('!'):
print 'end with ! ...';
#find
print s.find('or'); #7
#index, find a string and raise an exception if the string is not found
print s.index('or');
#join
c = '-';
print c.join(['a', 'b', 'c']);
#lower
print s.lower();
#replace
print s.replace('l', '-', 2);
#split
str = "Line1-abcdef, \nLine2-abc, \nLine4-abcd";
print str.split();
#strip
print ' Hello ... '.strip();
#upper
print s.upper(); #HELLO WORLD!
Regular Expression
Pattern
- ^, beginning of a line
- $, end of a line
- ., matches any single character except newline
- [...], matches any single character in brackets
- [^...], matches any single character not in brackets
- *, matches 0 or more occurrences of preceding expression
- +, matches 1 or more occurrence of preceding expression
- ?, matches 0 or 1 occurrence of preceding expression
- re{n}, match exact n time
- re{n, m}, matches at least n and at most m occurrences
- a|b, matches either a or b
- \w, match word characters
- \W, match none word characters
- <.*>, greedy repetition
- <.*?>, none greedy repetition, matches the smallest number of repetitions
Flags
- re.I, performs case-insensitive matching
- re.M, makes $ match the end of a line (not just the end of the string) and makes ^ match the start of any line
#!/usr/bin/python
import re;
phone = "2004-959-559 # This is Phone Number"
#match
m = re.match(r'(\d+)-(\d+)-\d+.*', phone);
if m:
print type(m);
print m.group(); #2004-959-559 # This is Phone Number
print m.group(1); # 2004
print m.groups(); # ('2004', '959')
#search
s = re.search(r'\d+', phone);
if s:
print type(s);
print s.group(); #2004
#findall
a = re.findall(r'\d+', phone);
print a; #['2004', '959', '559']
#replace
r = re.sub(r'\d', '*', phone);
print r; ****-***-*** # This is Phone Number
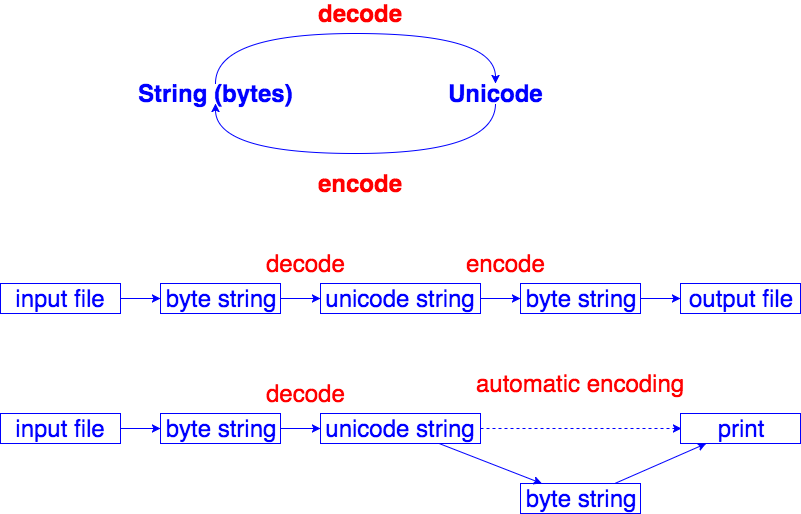
Unicode
a sequence of code points, immutable
Python keep characters as unicode in memory
String read from a file is byte string, need to be decoded to unicode
Output unicode to a file, need to encode to byte string
Print a unicode on console, it is encoded to byte string automatically by default encoding method
ord, convert a string to its unicode code point
unichr, convert an integer into a Unicode string
type 'str' represents byte string in Python 2, type 'unicode' represent unicode
#!/usr/bin/python
# -*- coding: utf-8 -*-
import sys;
# set up default encoding
reload(sys) # Reload does the trick!
sys.setdefaultencoding('UTF8')
print sys.stdout.encoding;
# unicode to str
s = 'Café';
print type(s), len(s); #'str', 5
s = u'Café';
print type(s), len(s); #'unicode', 4
print type(s.encode('utf-8')); #'str'
# read string from a file and print it to screen
f = open('temp.txt', 'rb');
l = f.next(); #read a line and save it to byte string
l = l.decode('utf-8'); #decode str to unicode
print type(l); #'unicode'
print l; #陈, print encode unicode to str with utf-8
f.close();
# get unicode code point
c = ord(u'陈'); #38472
print unichr(38472); #陈, do not print code point, it is encoded to str
codecs
Regular open() function is not able to read chunks since one unicode character can be represented by several bytes, which cause problems when read in the last character
If we read the whole file and encode, it may require a large memory
import codecs
f = codecs.open('codecs.html', encoding='utf-8', mode='r') # read line and decode to unicode
#for line in f: % codecs creates a buffer to read lines
#print repr(line)
outf = codecs.open('output.html', encoding='utf-8', mode='w+') # encode line and write to output file
for line in f:
outf.write(line)
outf.close()
f.close()
Reference