String
String
Strings of characters, immutable
s = 'Hello World!'
#access element
print(s[0]) #H
#slicing
print(s[:2]) #He
#slice
sl = slice(0, 10, 2)
print(s[sl]) #HloWr
#concatenation
print(s+' ...')
#repeat
print(s*2)
#in
if 'H' in s:
print('Contain H')
#raw string, suppresses actual meaning of escape characters
print(r'raw string\n')
s = 'raw string\n'
print('%r' % s) # output string as raw string
s = 'Hello World!'
#capitalize, capitalizes first letter of string
print(s.capitalize())
#center
print(s.center(20, '*'))
#count
print(s.count('l'))
#endswith
if s.endswith('!'):
print('end with ! ...')
#find
print(s.find('or')) #7
#index, find a string and raise an exception if the string is not found
print(s.index('or'))
#join
c = '-'
print(c.join(['a', 'b', 'c']))
#lower
print(s.lower())
#replace
print(s.replace('l', '-')) # replace all occurrences
print(s.replace('l', '-', 2)) # replace at most max occurrences
#split
str = "Line1-abcdef, \nLine2-abc, \nLine4-abcd"
print(str.split())
import re
# use multiple delimiter
print(re.split('\n|, ',str)) # ['Line1-abcdef', '', 'Line2-abc', '', 'Line4-abcd']
#strip
print(' Hello ... '.strip())
#upper
print(s.upper()) #HELLO WORLD!
# Template
from string import Template
s = Template('$fname, $lname, $fname')
sub = s.substitute(fname='Lin', lname='Chen')
print(sub) # Lin, Chen, Lin
Regular Expression
Pattern
- ^, beginning of a line
- $, end of a line
- ., matches any single character except newline
- [...], matches any single character in brackets
- [^...], matches any single character not in brackets
- *, matches 0 or more occurrences of preceding expression
- +, matches 1 or more occurrence of preceding expression
- ?, matches 0 or 1 occurrence of preceding expression
- re{n}, match exact n time
- re{n, m}, matches at least n and at most m occurrences
- a|b, matches either a or b
- \w, match word characters
- \W, match none word characters
- <.*>, greedy repetition
- <.*?>, none greedy repetition, matches the smallest number of repetitions
Flags
- re.I, performs case-insensitive matching
- re.M, makes $ match the end of a line (not just the end of the string) and makes ^ match the start of any line
import re
phone = "2004-959-559 # This is Phone Number"
# match
# match RE pattern to string
# checks for a match only at the beginning of the string
m = re.match(r'(\d+)-(\d+)-\d+.*', phone) # use () to group matches
if m:
print(type(m))
print(m.group()) #2004-959-559 # This is Phone Number
print(m.group(1)) # 2004
print(m.groups()) # ('2004', '959')
# search
# searches for first occurrence of RE pattern
# checks for a match anywhere in the string
s = re.search(r'\d+', phone)
if s:
print(type(s))
print(s.group()) #2004
#findall
a = re.findall(r'\d+', phone)
print(a) #['2004', '959', '559']
#replace
r = re.sub(r'\d', '*', phone)
print(r) # ****-***-***, This is Phone Number
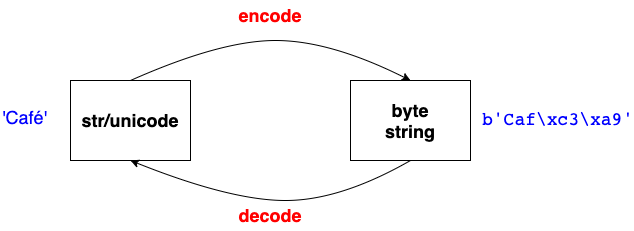
Unicode
a sequence of code points, immutable
Python keep characters as unicode in memory
type 'str' represents unicode in Python 3, type 'bytes' represent byte string
byte string can only contain ASCII literal characters
- Working with binary data, such as images, or audio files
- When sending or receiving data over network sockets
- When reading from or writing to binary files, such as reading an image file
- Cryptographic operations often work with binary data, and byte strings are used to hold the binary input, output, and intermediate values in these operations
- In some cases, using byte strings can be more memory-efficient and faster than using Unicode strings
# unicode and str
# same in Python 3
s = 'Café' # str
s = u'Café' # str
# byte string
s = b'lin' # bytes
# str to byte string
s = 'Café'
s.encode('utf-8') # utf-8 is the default encode standard
# byte to str
s = b'Caf\xc3\xa9'
s.decode('utf-8')
# get unicode code point
c = ord(u'陈') #38472, int
chr(38472)) #陈, str
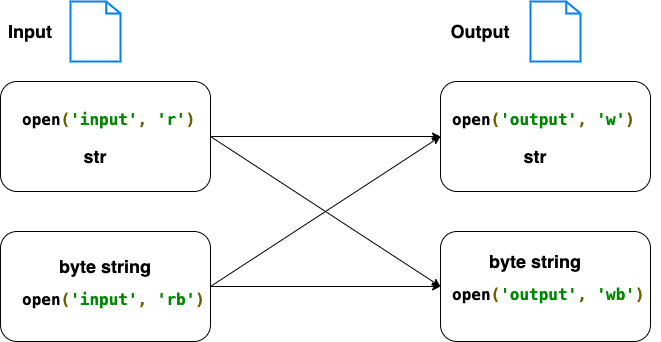
read str, output str
f = open('temp.txt', 'r') # read str
l = next(f)
o = open('output.txt', 'w') # write str
o.write(l)
o.close()
f.close()
read str, output byte string
f = open('temp.txt', 'r') # read str
l = next(f)
o = open('output.txt', 'wb') # write byte string
o.write(l.encode('utf-8'))
o.close()
f.close()
read byte string, output str
f = open('temp.txt', 'rb') # read byte string
l = next(f)
o = open('output.txt', 'w') # write str
o.write(l.decode('utf-8'))
o.close()
f.close()
read byte string, output byte string
f = open('temp.txt', 'rb') # read byte string
l = next(f)
o = open('output.txt', 'wb') # write byte string
o.write(l)
o.close()
f.close()
Reference